
2標本t検定によるサンプルサイズ計算
2標本t検定は、少ないサンプルサイズ、または正規性からの逸脱の両方に対する頑健性があるため、最も広く利用されている統計的検定の1つです。
チュートリアルでは、nQueryでサンプルサイズ計算を行う一般的な方法を説明した後、The New England Journal of Medicineに掲載された論文: Cyclophosphamide versus Placebo in Scleroderma Lung Disease(強皮症による肺疾患に対するシクロホスファミドの評価)を例に、nQueryによる2標本t検定のサンプルサイズ計算を紹介しています。
June 22, 2006、The New England Journal of Medicine (NEJM)
2006; 354:2655-2666 DOI: 10.1056/NEJMoa055120
このチュートリアルではnQueryのインターフェイスの説明を紹介した後、The New England Journal of Medicine (NEJM) に掲載された"Cyclophosphamide versus Placebo in Scleroderma Lung Disease"の事例を用いて、nQueryによるサンプルサイズ計算について紹介します。
nQueryインターフェイスの基本
分析方法を選ぶ
Homeウィンドウで Create a New Table をクリックすると、Select Testダイアログが開きます。
Select Testダイアログから、MTT-01/Two Group t-test of Equal Mean(等しい平均値の2標本t検定)を選択します。

メインテーブル
nQueryでは、新しいテーブルを開いたときにnQueryの左上隅にあるスプレッドシートでサンプルサイズ計算が行われます。
このスプレッドシートの各行はサンプルサイズまたは検出力の計算に必要な入力であり、各列は個々の計算に対応します。1列目の計算は 2列目、3列目などの計算から独立しています。
白で表示されている行には計算のための入力を行います。必要なすべての他のパラメータを入力すると、黄色で表示されている行にnQueryが計算した値が自動的に表示されます。

メインテーブルの行ラベルは分析を行うために必要なパラメータです。ここでは、サンプルサイズ計算を行うために次のパラメータが必要なことが分かります。
- 有意水準
- 片側検定か両側検定か
- 群1と群2の平均
- 平均の差
- 共通の標準偏差
- 効果サイズ
- 検出力
- およびサンプルサイズ

Helpウィンドウ
行を選択すると、右側のHelpウィンドウが自動的に更新されます。
Helpウィンドウには、定義、提案、および特定の行やパラメータに許容可能な入力値が表示されます。
例えば検定の有意水準αを選択すると次のように表示されます。
Alpah is the probabbility of rejecting the null hypothesis that the mean equals the specified value when it is true (the probability of a Type I error).
Suggestion
Enter 0.05, a frequent standard.
Acceptable Entries:
0.001 to 0.20
検定の有意水準、α
αは、「平均値が指定された値に等しい」という帰無仮説が真であるときにそれを棄却する確率(第一種エラーの確率)です。
提案
よく使われる基準である0.05を入力してください。
許容可能な入力値
0.001~0.20
サンプルサイズ計算では、試験を行う前に正しい値が何であるかが正確には分からないパラメータが存在します。そのような場合は、何が起こると期待されるか、何がその効果サイズについての最小の臨床的に関連する値であるかについて、意味のある推測を行う必要があります。

サンプルサイズ計算(2標本t検定)
臨床試験で用いられた統計に関する情報
The New England Journal of Medicine: Cyclophosphamide versus Placebo in Scleroderma Lung Disease
"We estimated that we would need to enrol 160 patients, given an expected mean (±SD) annual decline in the FVC of 9±16 percent of the predicted value and a dropout rate of 15 percent, to achieve a two-sided alpha level of 0.05 and a statistical power of 90%."| Parameter | Value |
| Significance Level (Two-Sided) | 両側有意水準 | 0.05 |
|---|---|
| Mean Difference (%) | 平均差 (%) | -9 |
| Standard Deviation (%) | 標準偏差 (%) | 16 |
| Dropout Rate | 脱落率 | 15% |
| Target Power | 目標とする検出力 | 90% |
データ入力
この事例では、最小の臨床的に関連する差は-9と想定されています。また、事前のエビデンスに基づいて、各群における標準偏差は16に等しいと仮定されています。
Difference in Meansの行に-9、Common Standard Deviationの行に16と入力すると、効果サイズ(Effect Size)が自動的に0.563と計算されます。
テーブルには群1と群2の平均の入力は任意のため、値が入力されていません。平均の差はこれら2つのパラメータを使用して計算できますが、この事例では平均の差が直接用いられています。

検出力について
この臨床試験では90%の検出力が望まれています。検出力は特定された対立仮説が真であるときに帰無仮説を棄却する確率です。つまり、平均の差が実際に-9以上で標準偏差が16に等しいとして、検出力90%を入力した場合、その平均の差と共通の標準偏差が実際に真であるとすると、有意なP値を得る90%の確率があることを望むのと同じことになります。
テーブルに検出力90%と入力すると、この差とこの標準偏差で90%の検出力を得るためには各群68人が必要ということが分かります。つまり、各群68人あれば、平均の差が-9で共通の標準偏差が16の場合 に90%の確率で有意なP値が得られます。

Outputウィンドウ:結果の記述
メインテーブルの下のOutputウィンドウには結果が文章で要約されます。
両側有意水準5%の2群t検定を用いて、各群のサンプルサイズが68であれば、共通の標準偏差が16であると仮定すると平均値の差-9を検出するための90%の検出力が得られます。

Outputウィンドウの右下にあるボタンや右クリックメニューを使用して、要約の編集、クリップボードへのコピーや印刷することができます。
Add to Note機能を使えば、現在の事例に関する注意書きを残しておくことも可能です。

グラフ機能
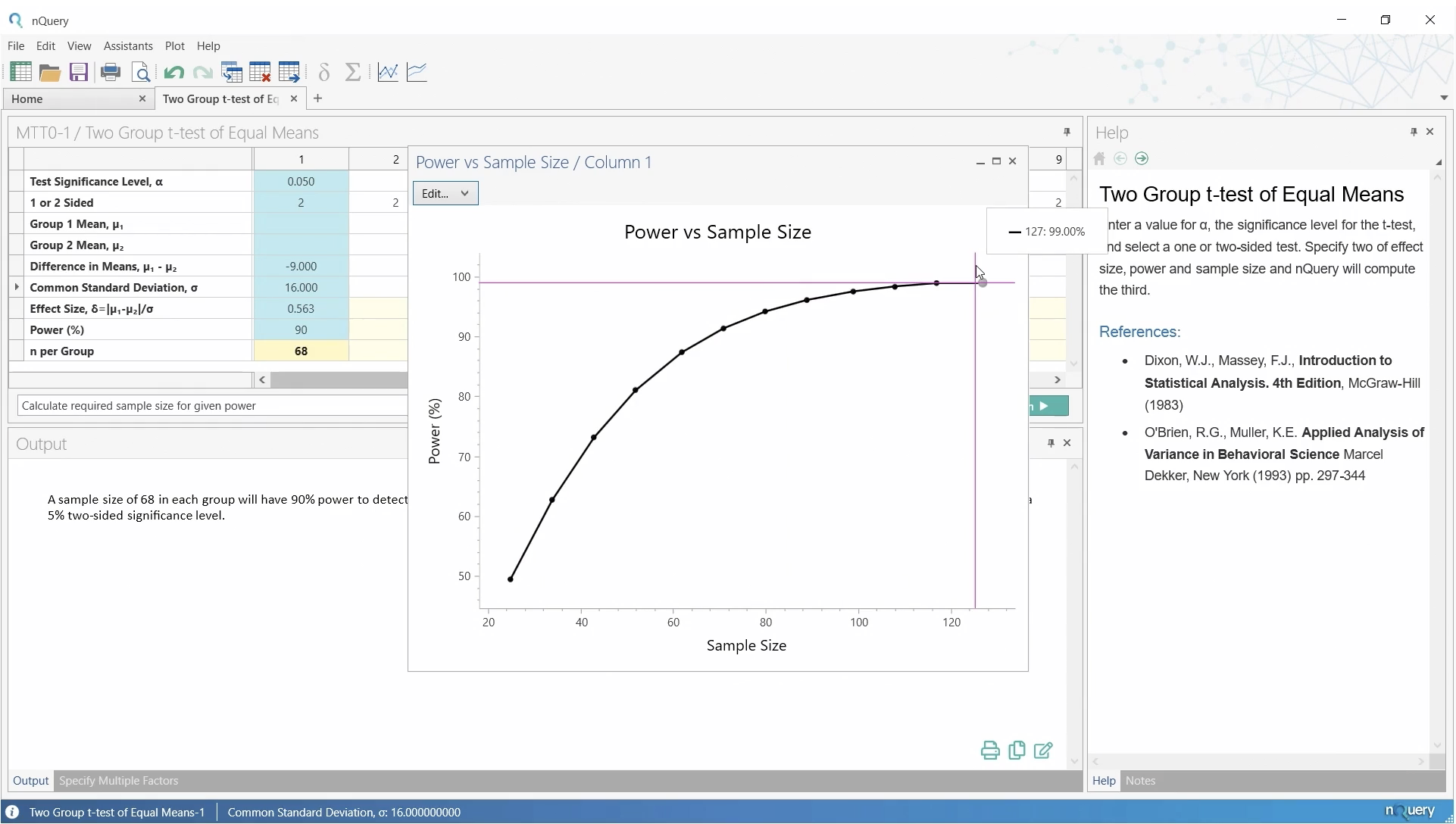
ここで Power vs Sample Sizeボタンをクリックすると、ツールバーから利用可能な検出力対サンプルサイズがプロットされます。
約50%から約99%までの範囲の検出力で必要なサンプルサイズが自動的にプロットされ、結果をさらに検討するのに役立ちます。

このプロットから、50%の検出力では25という小さいサンプルサイズが必要ですが、99%のかなり高い検出力では約127のサンプルサイズが必要になることが分かります。また、約90%の検出力でサンプルサイズは62から71の間になります。
プロットのタイトルや他の要素を編集する場合、左上隅のEditボタンをクリックします。
よりカスタマイズされたグラフをプロットする場合は、ツールバーのUser-Selected Rowsボタン をクリックし、Select X-axis, Y-axisダイアログからソルバーや出力に対する連続値の入力します。
をクリックし、Select X-axis, Y-axisダイアログからソルバーや出力に対する連続値の入力します。
例えば、元の標準偏差16から逸脱した場合のサンプルサイズへの影響を見たいときは、 X軸オプションとして共通の標準偏差を選択し、Y軸オプションとして群ごとのサンプルサイズを選択することができます。

0.1刻みで10から20の範囲の標準偏差に対するサンプルサイズへの影響について見てみましょう。
グラフが示すように、標準偏差が大きくなると必要サンプルサイズも大きくなります。標準偏差が20の場合、各群105人が必要となりますが、標準偏差が10の場合は各群27人しか必要ありません。

データの値を変し複数のシナリオを比較
Specify Multiple Factorsを使って、同じデータを評価することも可能です。
例として、標準偏差を10、12、14、16、18、20として、90%の検出力を設定してみましょう。 Specify Multiple Factorsに値を入力すると、メインテーブルにこれら6つのシナリオが自動的に表示されます。

nQueryによる2標本t検定のサンプルサイズ計算のチュートリアルは以上となります。
動画によるチュートリアル
Base | Plus | Pro | Expert