
nQuery9.3 新機能
https://www.statsols.com/whats-new
臨床試験に関わるリスクとコストが最適なバランスになるように、nQueryは継続的に機能が強化されています。関係を継続的な改善を行っています。nQuery 9.3 においても、固定デザインから柔軟な試験デザインまで、臨床研究・治験に携わる研究者のコスト節約・リスク軽減を支援する改善が行われています。

nQuery Pro に追加されたテーブル | New Pro Tables
グループ逐次デザインのオーバーホール | Overhauled Group Sequential Design
グループ逐次デザインは臨床試験・治験で最も一般的に使用される適応デザインです。グループ逐次デザインでは、治療が効果的である (efficacy - 有効性) か無効である (futility - 無益性) という十分なエビデンスがある場合、中間解析の早い段階で治験の中止を判断できます。グループ逐次デザインでは治験の早期中止が可能であるため、大幅なコスト削減につながると同時に、有効な治療法であればより早く患者の手に届けることができます。 Lan-DeMets法の α 消費関数などの方法によって、治験モニタリング中に大きな柔軟性を維持しながら、治験を早期に中止する条件を定義することができます。
nQuery 9.3 では、グループ逐次デザインのオーバーホール(見直し)が行われました。このオーバーホールには、グループ逐次デザインの方法の追加、ユーザーエクスペリエンスの大幅な改善、さまざまなグルー逐次デザインのシナリオをよりよく検討するための詳細出力の追加が含まれます。nQuery9.3 はオーバーホールの第一段階であり、今後のアップデートでは、追加のエンドポイント、グループ逐次デザインのメソッド、およびユーザー機能が拡張される予定です。
追加されたテーブル
- Group Sequential Design for Two Means
- Group Sequential Design for Two Proportions
- Information-Based Group Sequential Design
- 11 Spending Functions
O’Brien-Fleming, Pocock, Power Family, Hwang-Shih-DeCani, Exponential, Beta, t-distribution, Logistic, Normal, Cauchy, User Defined/Interpolated - Wang-Tsiatis & Pampallona-Tsiatis Designs
- Haybittle-Peto (p-value) Design
- Unified Family Design
- 境界デザインのカスタマイズ | Custom Boundary Design with custom Z statistic, p-value, Score Statistic or Effect Size boundary inputs
- 両側、層別無益性の境界 | 2-sided Futility Boundaries
nQuery Plus に追加されたテーブル | New Plus Table
パイロット試験用サンプルサイズ | Sample Size for Pilot Studies
パイロット試験は、計画された試験の前に実施され、本試験の実現性と実施された場合に予想される特性を評価するための小規模な試験です。
妥当なパラメータ推定値を得るために必要なパイロット試験の規模について、いくつかの経験則が提唱されています。 ただし、調査によると、これらは多くの現実世界のシナリオでは正しくないことがわかっています。 これに応じて、パイロット研究の推定値に予想される不確実性を考慮したパイロット研究に適切なサンプル サイズを見つける方法が開発されました。
nQuery 9.3 では、2 つの標本の t 検定を使用する主要な試験が実装される前にパイロット研究に必要なサンプル サイズを計算するための 2 つの一般的な提案があり、1 つは非中心 t 統計量に基づき、もう 1 つは上位信頼度に基づきます。 見積もりの限界です。 さらに、パイロットスタディにおける問題検出のための表と、直接的な上限信頼限界のための表も含まれています。
nQuery 9.3では、2標本のt検定を使用する本試験前のパイロット試験に必要なサンプルサイズを計算するため、2つの一般的な提案を行います。1つは非心 t 統計量に基づき、もう1つは推定値の信頼上限値に基づく提案です。さらに、パイロットにおける問題検出のための表と、上側信頼限界を直接求めるためのテーブルも含まれています。
追加されたテーブル
- Sample Size for Pilot Study for Two Sample t-test Trial (Non-Central t-distribution, Upper Confidence Limit)
- Error Detection in Pilot Study
- Sample Size for Upper Confidence Limit of Standard Deviation from Pilot Study
ベイズ統計 - 同等性 | Bayes Equivalence
2つの治療法で同等の結果が得られるかどうかを確認する同等性試験は、ジェネリック医薬品開発や医療機器などの分野で一般的な試験です。 現在、ほとんどの同等性試験は、二重片側検定 (TOST) などの頻度主義的な手法を使用するか、信頼区間が同等性の下限と上限内に収まるかどうかを確認することによって行われます。
ベイズ統計における Bayesian alternatives は、同等性をテストするために提案されています。 これには、「実質的な等価領域」(ROPE)やベイズ係数の使用などの提案が含まれます。 ROPE 法は、最高密度(HDI)信頼区間を使用する以外は信頼区間アプローチに類似しており、テストと推定の両方の段階で解釈可能性が改善されています。
nQuery 9.3には、ベイズROPE法を用いて同等性を評価する2群研究に必要なサンプルサイズを提供するテーブルが用意されています。
追加されたテーブル
- Equivalence Test for Two Means Using Baysian Region of Practival Equivalence (ROPE)
nQuery Base に追加されたテーブル | New Base Tables
割合 | Proportions
割合(i.e., カテゴリカルデータ)は、最も一般的な関心のあるエンドポイント、特に二項変数でよく使われるデータの種類です。 臨床試験の例には、腫瘍退縮のような対象反応を経験する患者の割合などが挙げれられます。バイナリ比率には、厳密なものから最尤法、正規近似まで、さまざまなデザインが提案されています。
nQuery 9.3 では、割合を含む試験のデザインについて、下記のエリアにサンプルサイズのテーブルが追加されています。
- Logistic Regression
- Confidence Interval for Proportions
ロジスティック回帰 | Logistic Regression
ロジスティック回帰は、反応率などのバイナリ評価項目の分析に最も広く使用されている回帰モデルです。この回帰モデルは、共変量として他の変数の効果を考慮しながら、複数のタイプの治療構成の効果を柔軟にモデル化することが可能です。
nQuery 9.3では、共変量調整分析および相加的相互作用効果を含むいくつかの追加ロジスティック回帰シナリオについて、Sample Size Determination (サンプルサイズの決定) が追加されました。
追加されたテーブル
- Covariate Adjusted Analysis for Binary Variable
- Covariate Adjusted Analysis for Normal Variable
- Additive Interaction for Cohort Design
- Additive Interaction for Case-Control Design
割合の信頼区間 | Confidence Interval for Proportions
信頼区間は、臨床研究で最も広く使用されている統計区間です。 統計的区間により、統計的推定値の不確実性の程度を評価することができます。割合については、研究デザインと望ましい運用特性に応じて、信頼区間を構築するための多くの異なるアプローチが提案されてきました。
nQuery 9.3 では層別化およびクラスター無作為化層別化デザインにおけるバイナリーエンドポイントについて、信頼区間の幅のためのSample Size Determination (サンプルサイズの決定) が追加されました。
追加されたテーブル
- Confidence Interval for Stratified Binary Endpoint
- Confidence Interval for Cluster Randomized Stratified Binary Endpoint
生存期間(Time-to-Event)分析 | Survival (Time-to-Event) Analysis
生存試験または Time-to-Event試験とは、死亡や腫瘍の退縮など、特定のイベントが発生するまでの時間をエンドポイントとする試験で、腫瘍学や心臓病学などの分野でよく使用されます。
nQuery 9.3 では、信頼区間の幅のSampe Size Determination(サンプルサイズの決定)が、階層化およびクラスターランダム化階層化設計のバイナリエンドポイントに追加されます。
追加されたテーブル
- Maximum Combination (MaxCombo) Tests
- Linear-Rank Tests for Piecewise Survival Data
- Paired Survival Data
MaxCombo検定 | Maximum Combination (MaxCombo) Tests
コンビネーション検定は、比例ハザード (PH) および 非比例ハザード (NPH) のパターンで、重みなし/重み付き log-rank検定でサンプルサイズを決定するアプローチです。
log-rank検定は、生存曲線の比較のために最も広く使用されている検定の1つですが、多くの線形順位検定法がlog-rank検定の代替として用いられています。別の検定法が利用される一般的な理由は、log-rank検定の実行が比例ハザード性の仮定に左右されてしまい、治療効果(ハザード比)が一定でなければ有意な検出力の損失を被る可能性が生じるためです。標準対数順位検定が各イベントに等しい重要性を割り当てるのに対して、重み付き対数順位検定は各イベントにあらかじめ指定された重み関数を適用します。しかし、非比例ハザードの種類が多いため(治療効果の遅延、効果の逓減、生存曲線の交差)、治療効果プロファイルがデザイン段階で不明な場合は最も適切な重み付きlog-rank検定を選ぶことは困難です。
Max-Combo検定は、検定統計量の相関による多重性を調整することで第一種過誤(Type-Ⅰ)を抑制しつつ、複数の検定統計量を比較し、データに基づいて最も適切な liner-rank検定を選択することができます。今回のリリースでは、最大組み合わせ検定の分野で新しいテーブルが1つ追加されています。
nQuery 9.3 では、nQuery 9.1 および 9.2 の不等式および非劣性の MaxCombo サンプル サイズテーブルに、MaxCombo テストを使用した同等性テスト用のサンプル サイズ決定テーブルを追加してます。
追加されたテーブル
- Equivalence Maximum Combination (MaxCombo) Linear Rank Tests using Piecewise Survival
区分的生存率のための線形順位検定 | Linear-Rank Tests for Piecewise Survival
nQuery 9.3では、9.2で追加された不等式(優越性)と非劣性の表に基づいて、同等性検定用の柔軟な区分生存を持つ7つの線形順位検定でサンプルサイズの決定が提供されます。
これらのnQueryテーブルを使用することで、Log-Rank、Wilcoxon、Taron-Ware、Peto-Peto、Fleming-Harrington、Threshold Lag、Generalized Linear Lag の達成検出力や必要なサンプルサイズを簡単に比較することができます。また、複数の検定を同時に評価することに関心がある場合に提供される MaxCombo テーブルを補完します。
追加されたテーブル
- Equivalence Linear Rank Tests using Piecewise Survival
Log-Rank, Wilcoxon, Tarone-Ware, Peto-Peto, Fleming-Harrington, Threshold Lag, Generalized Linear Lag
対応のある生存分析 | Paired Survival
Paired analyses are a common approach to increase the efficiency of trials by comparing the results between two highly related outcomes (e.g. from the same person). Where a paired analysis is appropriate, ignoring this pairing can lead to underpowered inference. For example, in ophthalmology survival type endpoints (e.g. time to vision loss/degradation) can occur where a different treatment is applied to each eye but the standard log-rank test is often incorrectly still used.
In nQuery 9.3, a sample size table for paired survival analysis using the rank test is added.
対応のあるペア分析は、関連性の高い 2 つの結果 (例: 同じ人物からの結果) 間の結果を比較することで、試験の効率を高めるための一般的なアプローチです。 ペア分析が適切な場合、このペアを無視すると、検定力が不十分になる可能性があります。例えば、 眼科におけるエンドポイント(視力喪失や視力低下までの時間など)は、それぞれの目に異なる治療が適用されているにもかかわらず、標準的なログランク検定がしばしば誤って使用されています。
nQuery 9.3 では、ログランク検定を使用したペア生存分析用のサンプルサイズテーブルが追加されています。
追加されたテーブル
- Test for Paired Survival Data
相関/一致/診断/分散 | Correlation/Agreement/Diagnostics/Variances
Correlation, agreement and diagnostic measures are all interested in the strength of relationships between two or more variables in different contexts. Correlation is interested in assessing the strength of the relationship between two variables.
相関、一致、診断の測定はすべて、異なるコンテクストの2つ以上の変数間の関係の強さに関心があります。相関は、2つの変数間の関係の強さを評価することに関心がある。
一致は、2人(またはそれ以上)の評価者(たとえば、2つの診断テスト)が、それらの評価を確実に再現できる程度を評価する。診断テストは、提案された評価者と真実(例えば、スクリーニングプログラムの結果と生検のような "ゴールドスタンダード "テスト)との間の一致の程度を比較する。
分散は、尺度のばらつきの程度を評価するために使用される。分散を比較する検定は、変動の量がグループ間で有意に異なるかどうかを評価するために使用できる。
Agreement assesses the degree to which two (or more) raters (e.g. two diagnostic tests) can reliably replicate their assessments. Diagnostic testing compares the degree of agreement between a proposed rater and the truth (e.g. screening programme result vs “gold standard” test such as biopsy)
Variance is used the assess the degree of variability in a measure. Tests comparing variances can be used to assess if the amount of variation differs significantly between groups.
In nQuery 9.3, sample size tables are added in the following areas for the design of trials using these concepts:
追加されたテーブル
- Equivalence Linear Rank Tests using Piecewise Survival
Log-Rank, Wilcoxon, Tarone-Ware, Peto-Peto, Fleming-Harrington, Threshold Lag, Generalized Linear Lag
nQuery9.2 新機能
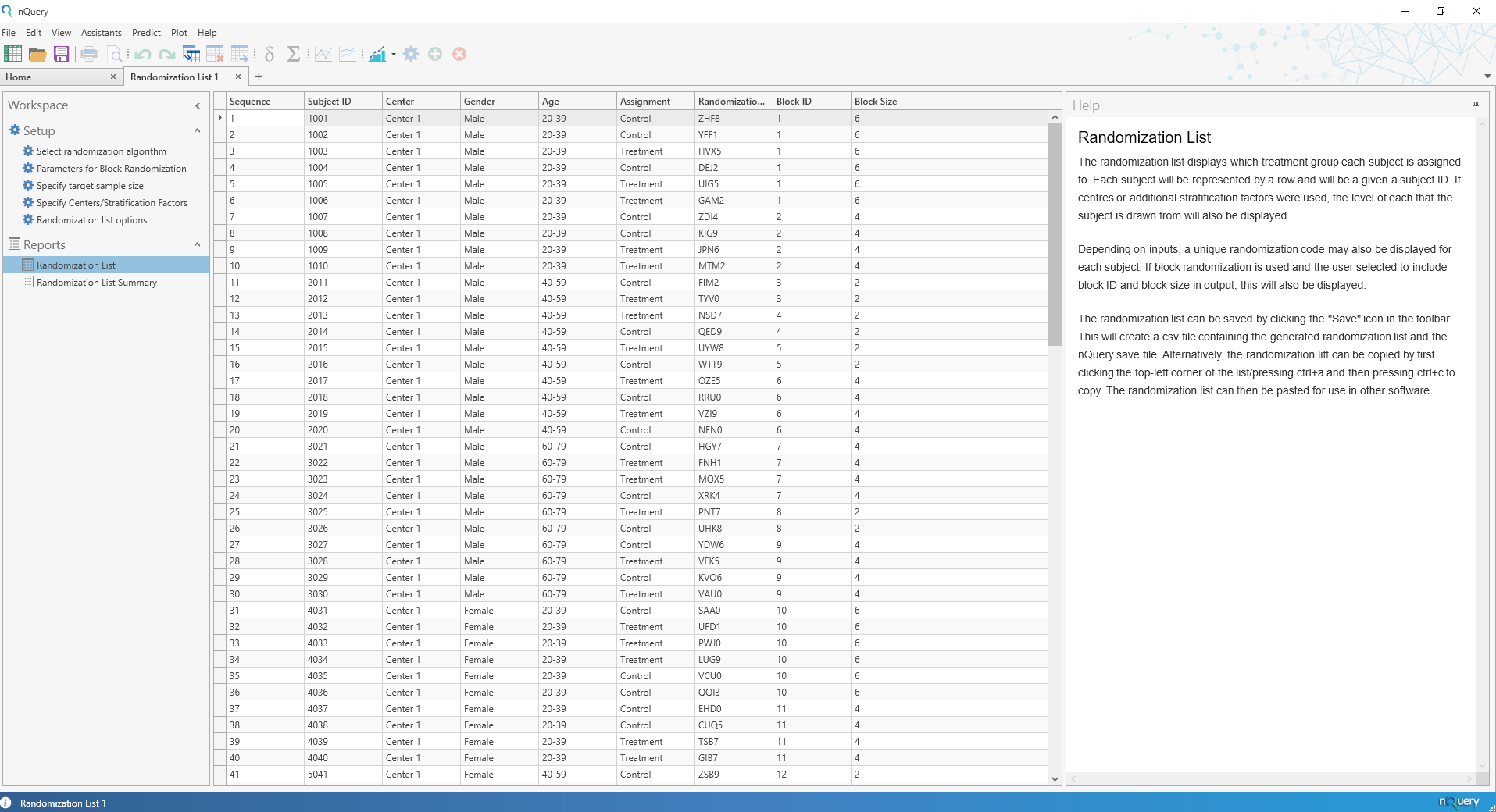
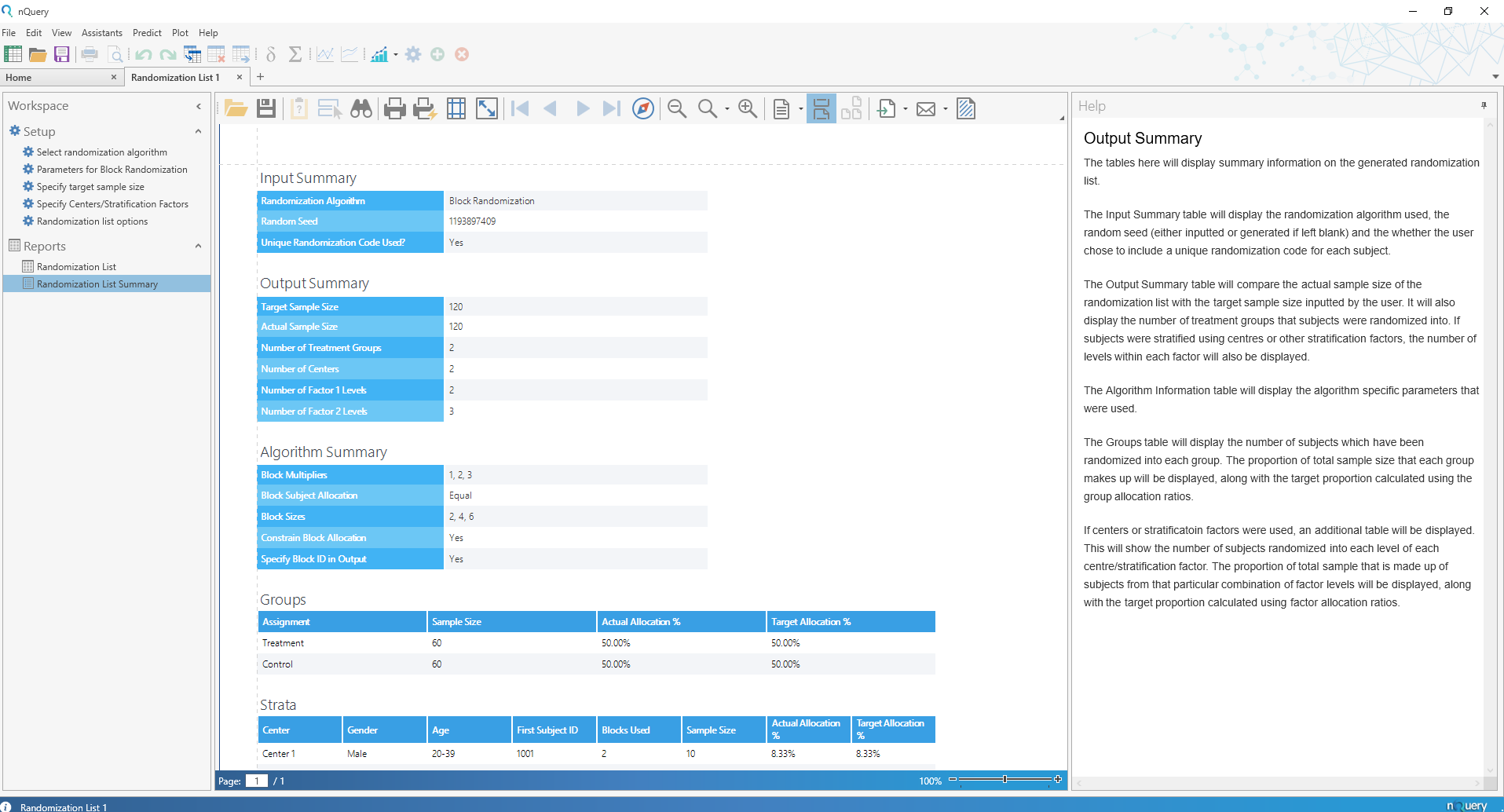
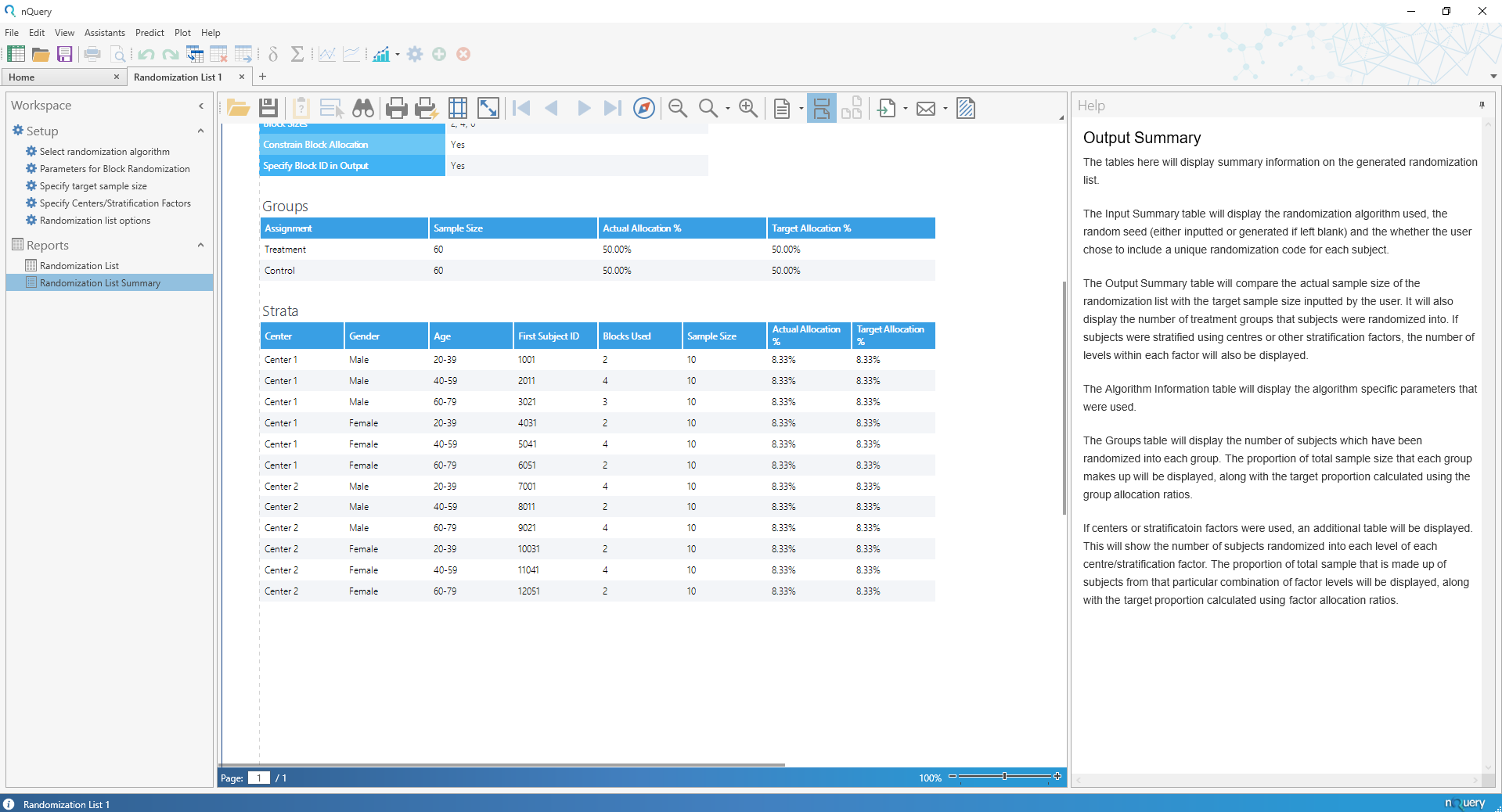
NEWS2022/7/27 に nQuery9.2がリリースされました。nQuery 9.2ではすべてのパッケージにランダム化リスト(Randomization Lists)ツールが追加されました。追加・強化された機能はこちらから:nQuery9.2リリースノート
臨床研究・治験に携わる研究者のコスト削減とリスク軽減を支援するため、nQueryは継続的に機能が強化されています。nQuery 9.2では ランダム化リスト(Randomization Lists)ツールと23の新しいサンプルサイズテーブルが追加されました。

ランダム化(無作為化)リスト | Randomization Lists Tool
Base、Plus、Pro すべてのパッケージ

nQuery 9.2では、ランダム化(無作為化)リストツールが追加され、無作為化と関心のある共変量のバランスを考慮したランダム化リストを簡単に作成できるようになりました。
初期リリースでは、以下のアルゴリズムで無作為化リストを生成する予定です。
- ブロックランダム化 | Block Randomization
- 完全ランダム化 | Complete Randomization
- Efronの偏コインランダム化法(2群のみ)| Efron’s Biased Coin (2 Groups Only)
臨床試験・治験で広汎的に利用される一般的な統計検定から有効な統計的推論を保証するため、ランダム化(無作為化)は臨床試験において不可欠です。ランダム化は比較可能な治療群を作り、未知の要因の影響を減らすことができますが、臨床試験においては、しばしば倫理的およびロジスティックな考慮事項があるため、単純なランダム化による割付が適切でない場合があります。
たとえば、臨床試験の実施中に時間的に変化する共変量の潜在的な影響を低減するため、または連続した分析が計画されている場合に任意の時点でバランスを維持することが重要であると考えられることがあります。さらに、性別などの共変量が全体的に比較的バランスが取れていることが重要なケースがあります。
ランダム化リストツールでは、最大25の治療法とセンター(病院など)、および最大2つの追加層別因子(年齢や性別など)を持つ試験のランダム化リストを作成でき、それぞれに最大25の層を生成することが可能です。さらに、アルゴリズム固有のオプション(ブロッランダム化のブロックサイズなど)や、ブロックや被験者レベルのIDを追加することで、関係者への理解や伝達を容易にする機能が提供される予定です。

アダプティブデザインテーブル追加 | 4 New Adaptive Tables
Proのパッケージ
nQuery Proに4 つの新しいサンプルサイズ表が追加されました。
- 盲検化されたサンプルサイズの再推定 x 2 | Blinded Sample Size Re-estimation x 2
- 二段階デザインによる生物学的同等性試験(BE試験)| Two-Stage Bioequivalence Testing (Potvin)
- 無増悪生存期間(PFS)のための第II相試験 | Litwin's Phase II Design for PFS
盲検化されたサンプルサイズの再推定
サンプルサイズの決定には、適切なサンプルサイズを見つけるために行われた仮定に対する不確実性のレベルが求められます。これらの仮定値の多くは、効果量に直接関係しない厄介なパラメータ(分散など)です。盲検化されたサンプルサイズの再推定は、研究の盲検化を解除することなく、これらの厄介なパラメータに対する改善された推定値を推定することができます。
罹患率(Incident rate)とインシデント数(Incident count)の分析に利用されるポアソン回帰モデルと準ポアソン(過分散)回帰モデルがあります。nQuery 9.2では、この2つのモデルに、内部パイロットアプローチを用いた盲検化サンプルサイズの再推定が導入されています。罹患率は、喘息やCOPDなどの呼吸器疾患の入院率や増悪率などの領域でよく用いられるエンドポイントです。インシデント数は、スクリーニングや診断(多発性骨髄腫による骨髄病変の数をMRIスキャンなど)などの領域における一般的なエンドポイントになります。
どちらのモデルでも、内部パイロットが全体のイベント率を再推定に用いられます。また、準ポアソン内部パイロットでは、過分散パラメータの推定値を得ることが可能です。
追加されたテーブル:
- Blinded SSR for Two Poisson Rates using Poisson Regression
- Blinded SSR for Two Poisson Rates using the (Overdispersed) Quasi-Poisson Regression Model

二段階デザインによる生物学的同等性試験(BE試験)
新しいジェネリック医薬品を承認するため、基本的に生物学的同等性試験(BE試験)のデータが必要となります。この試験は、薬物動態(PK)パラメータである曲線下面積(AUC)および最大濃度(Cmax)が同等であるかどうかを、2片側検定(TOST)または同等の信頼区間のアプローチで評価するものです。
クロスオーバーデザインは、各被験者があらかじめ指定された順序で複数の治療を受けるデザインです。最も一般的なクロスオーバーデザインは2x2デザインで、各被験者に治療が与えられ、半数は治療後にコントロール、残りの半数はコントロール後に治療が与えられます。ほとんどの生物学的同等性試験は、すべてのフォローアップが完了した後に分析が実施される固定期間クロスオーバーデザインによって行われます。
しかし、Diane Potvinなどの研究者により、2段階の生物学的同等性デザインが提案されています。これらの2段階デザインでは、生物学的同等性の早期評価と、最初のサンプルサイズ決定で分散の指定が誤っていた場合にサンプルサイズを適切に調整することの両方が可能です。
nQuery 9.2では、Potvin(2007)の決定スキームB、C、Dのデフォルトを使用して、2段階の生物学的同等性デザインの総合検出力や必要な第1段階のサンプルサイズを計算するためのテーブルが追加されています。また、Fulsang (2013)やKieser & Rauch (2015)などの他の2段階デザインを設計する柔軟性も備えています。
追加されたテーブル:
- Two-Stage Equivalence test for Two Means in a Crossover Design (Potvin's Design)

Litwinの無増悪生存期間(PFS)に関する第II相デザイン
第Ⅱ相試験は、新しい薬や治療法が、さらなる開発または評価を正当化するために有効性の基本的なレベルを満たす可能性の有無、そして第Ⅲ相で評価されるべき投与量を決定するためによく使用されます。
第Ⅱa相試験は、第Ⅱ相試験の概念実証の部分に重点をが置かれており、提案された治療法の潜在的な有効性と安全性を示すことを目的とします。概して第Ⅱ相は薬剤評価において最も失敗がみられます。無益性のために試験を早期に中止する柔軟性を可能にするために、2段階設計が一般的です。
nQuery 9.2では、第Ⅱa相試験における生存分析のための無増悪生存(PFS)の評価のために、Litwin(2007)が提案した2段階第Ⅱデザインが組み込まれています。このデザインにおいて、有効性は、初期および後期の時点で疾患の進行を経験していない(「無増悪」である)サンプルの割合として測定されます。無増悪の患者数が十分でない場合、無益性による早期中止が早期時点で検討されます。
無増悪生存期間(PFS)は、治療薬が病気の安定化につながりますが、必ずしも治癒には至らない場合に有用な臨床試験のエンドポイントです。例えば、癌治療における非細胞毒性抗癌剤は、腫瘍の縮小よりもむしろ長期の安定化をもたらすことが分かっています。
追加されたテーブル:
- Two Stage Phase II Design for Progression-Free Survival (Litwin's Design)

ベイズ推定・デザインテーブル追加 | 4 New Bayesian Tables
Plus, Proのパッケージ
nQuery Plusに4つの新しいサンプルサイズ表が追加されました。
- ベイズ平均誤差 x 3 | Bayesian Average Error x 3
- ベイズ因子による不等式検定 | Inequality Testing using Bayes Factor
ベイズ平均誤差
古典的なフレームワークでは、サンプルサイズの計算は、あらかじめ指定された 第一種過誤(Type-Ⅰ)と 第二種過誤(Type-Ⅱ)の確率を適切に維持することを目的としています。しかし、各誤差を個別に制御するこのアプローチには、必要以上に大きなサンプルサイズになることが多いといういくつかの欠点が存在します。このような制限から、いくつかのベイズ的な解決策が考案されました。
nQuery 9.2では、ベイズ平均誤差(BAE)法を使用したサンプルサイズの決定が導入されています。BAEは、 第一種過誤と第二種過誤の境界を個別に特定せず、全体の過誤率の目標レベルを維持するために必要な検定統計量のカットオフ値を自動的に決定します。
追加されたテーブル:
- Bayesian Average Error (BAE) for One Mean
- Bayesian Average Error (BAE) for One Proportion
- Bayesian Average Error (BAE) for Two Proportions
ベイズ因子
ベイズ因子はベイズ統計におけるp値として説明されています。ベイズ因子を用いると、対立仮説に有利な証拠しか見つからない頻度論的設定とは対照的に、帰無仮説に有利な証拠を評価することが可能です。
不等式(優越性)検定では、ベイズ係数は、対立仮説(つまり不等式)のもとで観測されるデータの確率と、帰無仮説(つまり等式)のもとで観測されるデータの確率の比として計算することができます。
nQuery 9.2では、2つの独立した平均を検定する場合のベイズ係数オプションにテーブルが追加されました。サンプルサイズは、ベイズ係数が事前に指定されたカットオフ値よりも大きいことを先験的に確率するように選択されます。
追加されたテーブル:
- Two-Stage Equivalence test for Two Means in a Crossover Design (Potvin's Design)
デザインテーブル追加 | 21 New Base Tables
Base、Plus、Pro すべてのパッケージ
nQuery Plusに15つの新しいサンプルサイズ表が追加されました。
- 8つのプロポーションテーブル:層別分析、順序データ、ペアプロポーション
- 7つの生存率テーブル:MaxCombo、線形順位検定、加速故障時間(AFT)モデル、複合エンドポイントに対するWin比(Win Ratio)
比率 | Propotion
比率(プロポーション)は、関心のある最も一般的なエンドポイントが二項変数である場合のデータの一般的なタイプです。臨床試験の例としては、腫瘍の退縮を経験する患者の割合があります。二値比率のデザインは、正確なものから最尤法、正規近似まで、幅広く提案されています。
追加されたテーブル:
- Stratified Analysis for Two Proportions
- Proportional Odds Model for Ordinal Data in Two Groups
- Tests for Paired Proportions
2つの割合の層別分析 | Stratified Analysis for Two Proportions
層別計画では、被験者は対照群と治療群に無作為に振り分けられる前に層別されます。これは、年齢、性別、体重や疾患の程度などの重要な共変量によって反応の割合が異なると考えられるからです。
2つのカテゴリー(例:はい/いいえ、基礎疾患あり/なし)を持つエンドポイントの分析を含む層別デザインで、最も一般的に用いられる分析として、Mantel-Haenzsel-Cochran検定が挙げられます。各層で一定のオッズ比を仮定すると、Mantel-Haenzsel-Cochran検定は、層にわたる効果について適切に重み付けされた検定統計量を分析することができます。
nQuery 9.2では、各層内のサンプルサイズが不均等な場合の不等性検定、非劣性検定、およびクラスター無作為化デザインについて、Mantel-Haenzsel-Cochran 検定を用いた層別デザインにおける2つの割合の分析のためのサンプルサイズ決定が提供されています。
層別計画における2つの割合の分析のためのサンプルサイズ決定を、Mantel-Haenzsel-Cochran 検定を用いて行うことができます。Mantel-Haenzsel-Cochran 検定は、各層内のサンプルサイズが不均等な場合の不等間隔検定、非劣性検定、クラスターランダム化デザインに対応しています。
nQuery 9.2では、各層内のサンプルサイズが不均等である場合、非劣性試験、クラスターランダム化デザインの場合に、層別デザインにおける2つの割合の分析に対して、Mantel-Haenzsel-Cochran 検定を用いたサンプルサイズの決定が不等式検定に提供されます。
追加されたテーブル:
- Mantel-Haenzsel-Cochran Test with Unequal Sample Size within Strata
- Non-inferiority Testing for S Strata using Mantel-Haenzsel-Cochran Test
- Mantel-Haenzsel-Cochran Test for S Strata in Cluster Randomized Design
順序データに対する比例オッズモデル | Proportional Odds Model for Ordinal Data
順序付きカテゴリカルデータは、反応が何らかの方法で順序付けされ、別々のカテゴリに分割される場合に発生します。これは、痛みや精神疾患の診断などの分野でよく見られるデータです。例えば、患者が調査に参加し、自分の反応を「良い」「中程度」「悪い」と表現する場合があります。
比例オッズモデルは、順序データの分析に広く使用されている方法です。比例オッズモデルでは、あるグループが他のグループと比較して、患者があるカテゴリ以下になるオッズ比が一定であると仮定します。言い換えると、各グループの累積比率を比較するオッズ比は、1からk-1までのすべての順序カテゴリについて一定です(累積比率は、最後のk番目のカテゴリで1に等しくなければなりません)。
nQuery 9.2では、Whitehead (1993)の手法を用いた比例オッズモデルによる2群間の順序データの分析、および同等のクラスターランダム化計画のためのサンプルサイズの決定が可能です。
追加されたテーブル:
- Test for Two Ordinal Variables with Proportional Odds Model
- Test for Two Ordinal Variables with Proportional Odds Model in Cluster Randomized Design
一対の割合の検定 | Tests for Paired Proportions
一対の(相関)比率は,2分値変数の結果が相関測定値間で比較される分析を指します。たとえば、臨床試験における各被験者の介入前と介入後に行われた測定値です。
McNemar検定は、対応のある比率の検定で最もよく用いられます。しかしながら McNemar検定は、ある対象の被験者における全ての観察が正常に行われた2つのカテゴリのみを扱います。 これらの制限に対処するために McNemar検定の拡張が提案されてきました。
複数カテゴリでは、相関のある2つの測定値を分析するために、McNemar Bowker検定が提案されました。この検定では、結果のk×k(k = カテゴリの数)分割表で対称性の検定が行われます。
不完全な観察については、部分的にしか観察されないペアによって提供される情報を使用する McNemar検定の拡張が、Thompson (1995), Ekbohm (1982) および Choi and Stablein (1982) で与えられました。これらの検定は完全データと部分データから2つの周辺確率の推定を必要とし、これらの2つの推定値の差が検定に使用されます。
nQuery 9.2では、複数カテゴリに対するMcNemar Bowker検定と、不完全な観察がある場合に提案される検定を用いて、対応のある比率分析のサンプルサイズの決定を行うことができます。
追加されたテーブル:
- Test for Two Ordinal Variables with Proportional Odds Model
- Test for Two Ordinal Variables with Proportional Odds Model in Cluster Randomized Design
生存期間(Time-to-Event)分析 | Survival (Time-to-Event) Analysis
生存試験または Time-to-Event試験とは、死亡や腫瘍の退縮など、特定のイベントが発生するまでの時間をエンドポイントとする試験で、腫瘍学や心臓病学などの分野でよく使用されます。
nQuery 9.2では、生存分析を含む試験の設計のために、以下のエリアにサンプルサイズのテーブルが追加されています。
追加されたテーブル:
- Maximum Combination (MaxCombo) Tests
- Linear-Rank Tests for Piecewise Survival Data
- Win Ratio for Composite Endpoints
MaxCombo検定 | Maximum Combination (MaxCombo) Tests
コンビネーション検定は、比例ハザード (PH) および 非比例ハザード (NPH) のパターンで、重みなし/重み付き log-rank検定でサンプルサイズを決定するアプローチです。
log-rank検定は、生存曲線の比較のために最も広く使用されている検定の1つですが、多くの線形順位検定法がlog-rank検定の代替として用いられています。別の検定法が利用される一般的な理由は、log-rank検定の実行が比例ハザード性の仮定に左右されてしまい、治療効果(ハザード比)が一定でなければ有意な検出力の損失を被る可能性が生じるためです。標準対数順位検定が各イベントに等しい重要性を割り当てるのに対して、重み付き対数順位検定は各イベントにあらかじめ指定された重み関数を適用します。しかし、非比例ハザードの種類が多いため(治療効果の遅延、効果の逓減、生存曲線の交差)、治療効果プロファイルがデザイン段階で不明な場合は最も適切な重み付きlog-rank検定を選ぶことは困難です。
Max-Combo検定は、検定統計量の相関による多重性を調整することで第一種過誤(Type-Ⅰ)を抑制しつつ、複数の検定統計量を比較し、データに基づいて最も適切な liner-rank検定を選択することができます。今回のリリースでは、最大組み合わせ検定の分野で新しいテーブルが1つ追加されています。
nQuery 9.2では、nQuery 9.1の不等間隔MaxComboサンプルサイズ表に加えて、MaxCombo検定を用いた非劣性試験のサンプルサイズ決定表を追加しています。
追加されたテーブル:
- Non-Inferiority Maximum Combination (MaxCombo) Linear Rank Tests using Piecewise Survival
区分的生存率のための線形順位検定 | Linear-Rank Tests for Piecewise Survival
nQuery 9.2では、不等間隔(優越性)検定と非劣性検定の両方で、柔軟な区分生存による7つの線形順位検定についてサンプルサイズの決定が提供されています。 これらのnQueryの表は、Log-Rank、Wilcoxon、Tarone-Ware、Peto-Peto、Fleming-Harrington、Threshold Lag、Generalized Linear Lagで得られる検出力や必要なサンプルサイズを簡単に比較できるほか、複数の検定を同時に評価する際に提供されるMaxCombo表を補完するために使用することができます。
追加されたテーブル:
- Inequality Linear Rank Tests using Piecewise Survival (Log-Rank, Wilcoxon, Tarone-Ware, Peto-Peto, Fleming-Harrington, Threshold Lag, Generalized Linear Lag)
- Non-Inferiority Linear Rank Tests using Piecewise Survival (Log-Rank, Wilcoxon, Tarone-Ware, Peto-Peto, Fleming-Harrington, Threshold Lag, Generalized Linear Lag)
複合エンドポイントの Win Ratio (Win比)| Win Ratio for Composite Endpoints
Win Ratio(Win比)は、複数の階層的エンドポイントを分析するための統計です。複合エンドポイントとは、複数の臨床エンドポイントを組み合わせたエンドポイントです。階層的とは、複合エンドポイントを構成するエンドポイントが、最も重要なものから最も重要でないものへと順番に並んでいることを指します。例えば、循環器内科では、最も優先度の高いエンドポイントは死亡になり、フォローアップで死亡が確認されない場合は、心不全が次に優先度の高いエンドポイントになります。
Win Ratio を用いた2つの独立したグループの比較では、治療グループの各被験者が、最も優先順位の高いエンドポイントの下でコントロールグループの各被験者と1対1で比較されます(これにより、p(1-p)N^2 の合計比較が得られます。ここで、p はグループ 1 の被験者の割合です)。これらの各比較は、「勝者(Winner)」、「敗者(loser)」、結果が不確定の場合は「同点(tie)」のいずれかに分けられます。同点が見つかった場合は、次に優先度の高いエンドポイントの下で比較されます。すべてのエンドポイントが評価され、最も優先度の低いエンドポイントに基づいて決定が行われるまで繰り返されます。
nQuery 9.2では、Win Ratio を用いた独立2群間の複合エンドポイントの分析、および同等の2群層別計画のためのサンプルサイズのテーブルが用意されています。
追加されたテーブル:
- Test for Two Groups Using Win Ratio
- Test for Two Groups Using Win Ratio using a Stratified Design