



主成分分析(PCA)の概要
GraphPad Prism9 に主成分分析(PCA)が新たに追加されました。多変量解析の一つでもある主成分分析は、データからできる限り情報を排除しつつ、必要な変数を減らす「次元削減」または「次元の縮約」と呼ばれる手法です。
例えば、数百から何千と異なる遺伝子発現量を、2つのグループに分けて測定する遺伝子発現の研究を行う場合、データをモデルにフィットさせるには変数が多すぎるかもしれません。しかし、いくつかの変数を選択して分析から除外することは、有益な可能性のある情報を捨てていることになります。主成分分析は情報の損失を抑え、できるだけ少ない変数に置き換えて分析を行います。
主成分分析の主な目的は以下の通りです。
- 探査分析のためにデータを視覚化します。スコアプロットを使用して任意の2つの主成分に沿ってデータの行をプロットするか、負荷量プロットを使用してデータの列をプロットすることにより、データの興味深い特性を見つけることができます。
- 今後の分析(例えば主成分回帰分析)のために予測子の数を減らします。
主成分分析と主成分回帰
主成分分析自体では、ほとんどの統計学のモデルとは異なり応答変数を定義する必要がない代わりに、変数の全ては予測子として入力されます。多くの場合、主成分分析は後に続く解析に先行するものとして使用され、主成分分析の後に実行される分析としては主成分回帰(PCR)が最も一般的です。主成分回帰の実行には結果変数を指定する必要がありますが、結果変数を主成分分析(PCA)に入力された変数の1つに指定することはできません。
主成分分析と因子分析
因子分析は社会科学で一般に普及しており、因子と呼ばれる変数間で解釈可能な線形関係(共通の因子)を見つけ出そうとします。言い換えれば、因子分析は、直接測定できない「根底にある」または「潜在的な」因子であるものの、データセット内の変数の測定値にパターンを引き起こすという概念に頼っているということです。PCAにおける主成分では同じような解釈はされません。PCAは観測された変数の数を減らし、より小さな独立変数のセットにするというシンプルなプロセスです。主成分分析での利点は、スコア、負荷量とバイプロットと、次元を減らしたスコアを用いて今後の解析を実行する能力です。(GraphPad Prismは因子分析にはまだ対応していません)
主成分分析:観測変数に共有する情報を統合し集約
因子分析: 観測変数に共通した潜在的な要因を抽出
操作手順: 主成分分析(PCA)
1. サンプルデータの選択
WelcomeダイアログのNEW TABLE & GRAPHより Multiple variables を選択します。
ここではサンプルデータを使用しますので、Data table: から Start with sample data to follow a tutorial を選び、Select a tutorial dataset:のリストから Principal Component Analysis(text variables)を選択します。
2. 主成分分析(PCA)を実行
サンプルデータにはすでにデータが用意されています。データテーブルを表示した状態で、ツールバーの分析/Analyzeセクションで、主成分分析ボタン![]() をクリックすると、ワンクリックでParameters: Principal Component Analysisダイアログが開きます。
をクリックすると、ワンクリックでParameters: Principal Component Analysisダイアログが開きます。

または、ツールバーにある Analyzeボタン  をクリックし、Analyze Dataダイアログを表示します。
をクリックし、Analyze Dataダイアログを表示します。
Multiple variable analyses の一覧の中からPrincipal Component Analysisを選択すると、Parameters: Principal Component Analysisダイアログが表示されます。

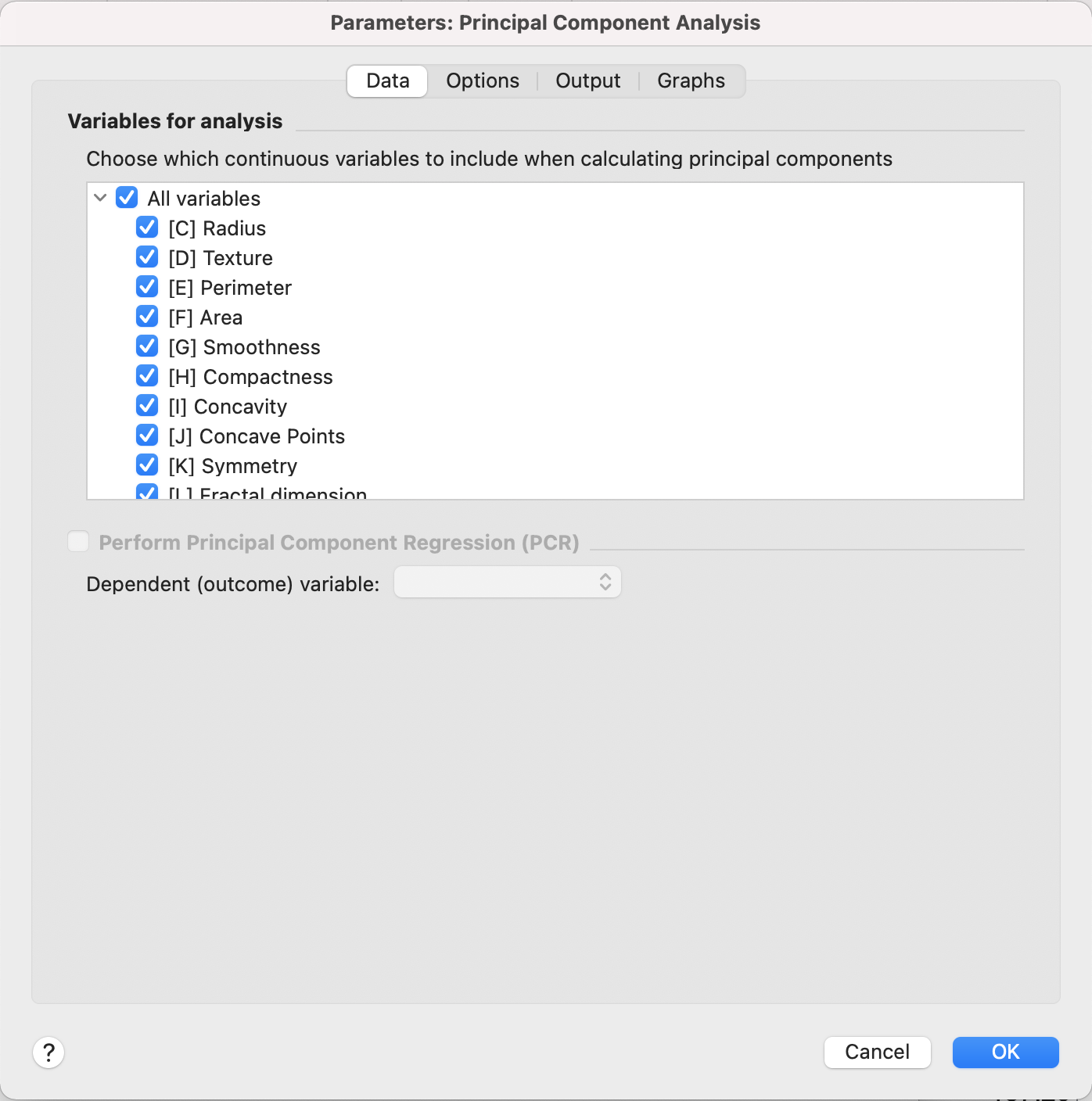
3. パラメータ:Dataタブ
Dataタブでは、主成分分析で使用される測定変数(予測変数、単にX変数と呼ばれることもあります)を指定します。分析は完全に測定変数の上で実行され、変数の根本的な構成を決定し、変数や行の集まりを特定して、データを可視化することができます。
Variable for Analysis | 分析のための変数
主成分分析では、少なくとも2つの連続変数を選択します。カテゴリー変数は、主成分分析を使用して分析されることはできません。主成分分析では、応答や、Y(変数)を指定する必要はないことを忘れないでください。主成分分析の実行を考える場合、分析のための変数を選択するとき、従属(アウトカム)変数を選択しないでください 。
Perform Principal Component Regression (PCR) | 主成分回帰(PCR)の実行
次元を減らした主成分スコア上で主成分回帰(PCR)を実行したい場合、このオプションにチェックを入れ、従属(アウトカム)変数を選択します。従属変数は連続変数である必要があり、変数のリストからは選択できないため、分析を行う変数には含まれない連続変数からのみ選択できます。
4. Optionsタブ
Optionsタブで、主成分分析の結果と結論に非常に影響する大きな2つの決定を行う必要があります。「なぜこれらを決定するのか」についてを理解していないのであれば、標準化されたデータで主成分分析を実行して、平行分析を使用して成分の数を選択することを推奨します。
Method | 手法
最も重要な決定は、主成分分析を標準化されたデータで行うのか、中心化されたデータで行うのかの決定です。
- 標準化されたデータでの主成分分析
- 特に理由がない限り、これが推奨される方法です。相関行列での主成分分析の実行と呼ばれることもあります。変数が異なる単位を使用して測定された場合、ほとんどの場合、この方法を選択します。 動作原理:主成分分析を実行する前に、各々の変数で平均値が0、標準偏差が1になるように変数は変換されます。これにより、すべての変数が同じスケールに配置されるため、主成分が見つかったときに、各々の変数に均等に重みが付けられます。数学的に言うと、 Xstandardized = (Xraw - X̄)/sx ここで、 X̄は平均値で、sxは変数の値の標準偏差です。
- 中心化されたデータの主成分分析
- 変数が全てが同じ単位であるとき、中心化されたデータの主成分分析、あるいは共分散行列の主成分分析と呼ばれる分析を行うかもしれません。これが適切な選択である場合もありますが、それは稀です。 動作原理:主成分分析を実行する前に、不変の標準偏差によって、各々の変数の平均値が0となるように変数は変換されます。変数はスケーリングされないため、他の変数よりも標準偏差が大きい変数は、初めに最初の主成分の計算を実行します。数学的に言うと、
Xcentered = (Xraw - X̄)
ここで、 X̄ は変数の平均値です。Method for selecting principal components (PCs) | 主成分の数を選択するための手法
主成分の選択は、主成分分析に続く次元が縮小されたデータセットが持つ”次元”の数を決定するプロセスです。ある場合には、Prismは選択された主成分の結果(負荷量、固有ベクトル、変数の相関行列、変数と主成分の相関行列、主成分スコアとケースの寄与率行列)だけを提供します。
Prismは、主成分の数を選択するために4つの方法を提供します:
- Select PCs based on parallel analysis | 平行分析に基づいて主成分を選択する(推奨)
- 平行分析は、シミュレーションによるノイズによって生成された主成分との区別できない主成分のポイントを決定することにより、含める主成分の数を選択する洗練されたシミュレーション手法です。平行分析がどのように機能するかのプロセスは次のとおりです。
平行分析を選択する場合、主成分の数を決定するために、スクリープロットはデータからの固有値に加えシミュレーションされた固有値を表示することに注意してください。
- Prismは、たくさんのデータセット(デフォルトは1000ですが、別の数も指定できます)をシミュレーションします。各々のシミュレーションされたデータセットには、入力データとして同じ数の変数(列)と観測(行)が含まれます。
a. 各々のシミュレーションされた変数について、データは、サンプリングによる多次元正規分布から平均値 = 0で生成されます。
b. 各々のシミュレーションされた変数の標準偏差は、入力データテーブルで、対応する変数の標準偏差と等しくなります。- 主成分分析は、各々のシミュレーションされたデータセットに対し実行されます。
- 各々の主成分について、平均固有値は、シミュレーションされたデータセット全体から計算されます。
- 各々の主成分について、上側パーセンタイル値(デフォルトは95パーセンタイル値)は、全てのシミュレーションされたデータセットでの固有値を使用して計算されます。
- 各々の主成分について、Prismは、入力データの固有値を、シミュレーションされたデータセットから計算された上側パーセンタイル値で比較します。
- 入力データの固有値が、シミュレーションされたデータセットから計算された上側パーセンタイル値より大きい場合、その成分が選択され、他に、成分は選択されません。
- Select PCs based on eigenvalues | 固有値に基づいて主成分を選択する
- 古典的には、固有値が1より大きい主成分が選択されます。これは、カイザー基準と呼ばれます。カットオフとして’1’を使用する動機は、標準化されたデータでは、各変数の標準偏差(と、分散)が1に等しいことです。主成分の固有値は、主成分が元々のデータを表す分散を表します。したがって、各々の元々の変数(または、列)による導かれる変動の量が1であるとき、固有値が1未満の主成分はデータの一つの列より変動がより少ないことを説明します。Prismでは、別のカットオフ値を選択するか、最大の固有値による最初のk個の主成分を保持するか(kはオプションで指定)をオプションで選択できます。
- Select PCs based on percent of total explained variance | 説明された分散の合計のパーセントに基づいて主成分を選択する
- もう一つの一般的な(古典的な)手法は、主成分の数を選択するために総分散の指定されたパーセントを累積的に説明する 最も大きい固有値で主成分を保持することです。総分散のターゲットパーセントのための一般的な選択は、75%と80%です。
- Select all PCs (Not recommended. For exploration purposes only) | すべての主成分を選択する (非推奨。研究目的のみ)
- 最後のオプションでは、 全ての主成分を出力させます。これはほとんど有用ではありませんが、教育目的、あるいは、ニッチデータ調査のために有用である場合があります。

5. Outputタブ
Outputタブでは、主成分分析による出力をカスタマイズし、結果の表に含める追加の変数を定義できます。追加された変数は、グラフにしたりその後の分析のために使用することができます。
- Additionally report | 追加する出力
- オプションの結果の表を出力するかどうかを選択します。これらの表の一部には、計算の”バックグラウンド”で使用されるデータが含まれていますが、その他の表はエキスパートユーザー向けであり、多くのPrismユーザーには必要ありません。
- Standardized/centered data | 標準化/中心化データ:これは、主成分分析計算に実際に入力される変換されたデータです。
- Eigenvectors | 各々の主成分の固有ベクトル:これらの値は、各々の主成分を定義する変数の線形結合の係数を提供します。
- Contribution matrix of variables | 変数の寄与率行列:各々の行は1つの変数を表し、各々の列は1つの主成分を表します。一つの列での値は、各々の変数が寄与する主成分によって説明される総分散の割合を表します。そのため、これらの値の合計は1.0(主成分によって説明される分散の100%)になります。数値的には、これらの値は固有ベクトルテーブルでの対応する値の二乗です。
- Correlation/covariance matrix between variables | 変数間の相関/共分散行列」:各々の行は1つの変数を表し、各々の列は1つの主成分を表します。各々の値は、対応する相関係数です。標準化されたデータについてのこの表は、負荷量(Loadings)行列と同じです。
- Contribution matrix of cases | ケースの寄与率行列:各々の行は1つのケース(元々のデータテーブルでの行)を表し、各々の列は1つの主成分を表します。一つの列での値は、各々のケースが寄与する主成分によって説明される総分散の割合を表します。そのため、これらの値の合計は1.0(主成分によって説明される分散の100%)になります。
- Correlation/covariance matrix between variables | 変数間の相関/共分散行列:各々の行は、 各々の列と同じように変数を表します。データが標準化されるとき、各々の値は2つの変数間での相関係数です。対角成分(行と列が同じ変数)は、常に1.0です。これは、その名称の分析から得ることができる同じ相関行列です。データが中心化されるとき、各々の値は2つの変数の間での共分散です。この場合、対角成分は元の変数の分散を表します(分散= [標準偏差]2)。

- Additional variables for graphing (PC scores table) | グラフにする追加の変数 (主成分スコアテーブル)
- Labels | ラベル:行の識別子(例えば行番号、名称、または、ID番号)。これらは各データポイントの隣に配置されます。
- Symbol fill color | シンボルの塗りつぶし(カテゴリー変数、または、連続変数)。Format Graphダイアログで、カラーマップを定義することができます。
- Symbol size | シンボルサイズ:バブルプロットの上でバブルの大きさをスケーリングします(カテゴリー変数、または、連続変数)。Format Graphダイアログで値を大きさに変換するための設定を見直します。
- Connecting lines |接続線:バブルプロット上の点の異なるグループ間の接続線をプロットします(カテゴリー変数のみ)。Format Graphダイアログで、選択されたカテゴリー変数の各々の水準について、接続線の外観を選択できます。
グラフを洗練するためにオプションの変数を選択します。

6. Graphsタブ
主成分スコアを継続解析のために使用する計画がない限り、グラフは主成分分析において重要な結果になります。主成分分析による生成されるグラフには次のものが含まれます。
- Score Plot | スコアプロット
- スコアプロットは、データの行を選択された主成分軸に沿ってプロットするために使用されます。このプロットは、データを低い次元で表現します。これは主に、選択した2つの成分に沿って、特定のポイントが他のポイントとの関係で、どこに表示されるかに基づいて、クラスタリングや他の意味を導き出すのに便利です。Prismでは、カーソルを関心のあるポイントに合わせると、データテーブル内の関連する行または列へのリンクを取得できます。このプロットのベースとなるのは、バブルプロットで、非常に柔軟性があります。
- Loadings Plot | 負荷量プロット
- 負荷量プロットは、単純に、指定された主成分の負荷量/Loadingsの数値をプロットします。主成分スコアプロットは、データの行を表す方法(主成分に沿って回転)にいくぶん類似しており、負荷量プロットは列に関する情報を提供します。負荷量は、データと主成分の列間の相関(または、共分散)です。変数の集まりを特定するのに、このプロットは有用です。
- Biplot | バイプロット
- バイプロットでは、主成分のスコアと負荷量を同じグラフにプロットできるように負荷量は乗数でスケーリングされます。これは主成分分析では通常の表示であるためPrismでも組み込まれていますが、ほとんどの場合で負荷量と主成分スコアは別々にプロットすることを推奨します。
- Scree Plot | スクリープロット
- スクリープロットは、含める主成分の数を決定するために主成分分析で伝統的に使用されています。スクリープロットを使用して主成分の数を選択する(非推奨)には、視覚的に、固有値が急な降下を終えて、水平になり始めるポイントを決定します。曲線が平らになり始める前の、曲線に沿ったすべての主成分は保持しますが、曲線が「急」から「平ら」に変化する主成分は含めないようにしてください。この場合は最初の2つの主成分だけを保持します。
- Proportion of variance | 寄与率プロット
- 寄与率プロットはスクリープロットに似ていますが、固有値をプロットする代わりに、各々の主成分による説明される寄与率をプロットします。この寄与率は、全ての主成分についての固有値の合計で、その主成分についての固有値を割ったもの(パーセントで出力されます)に等しくなります。このグラフには、累積総額の棒グラフも含まれます。たとえば、以下のプロットは、最初の2つの主成分が入力変数による総分散の約80%を説明していることを示しています。

Prism Statistics Guide: Overview of Principal Component Analysis